堆和栈简介
每个进程有一些可以使用的地址集合,典型值从0到某个最大值,叫做地址空间。这是操作系统为进程提供的一个抽象,是以进程的视角所看到的系统中的内存。
一个进程的地址空间通常包括代码段、数据段、堆、栈,地址从低到高。
注意这里的堆和栈不同于数据结构中的堆和栈。
代码段:可执行的代码
数据段: 1.数据段:已初始化的,且初值为非0的全局变量(static变量)
2.bss段:未初始化,或者初值为0的全局变量 (static变量)
堆:可以理解为程序员在程序中自己为变量分配的内存(需手动释放)
栈:保存了函数被调用时所需要的局部变量,函数参数,返回地址。
该进程在派生出很多线程时,线程栈也保存在这里。
除了这些之外,夹在stack和heap之间还有一个内存映射段(mmap)
下面是一个C程序的地址空间布局: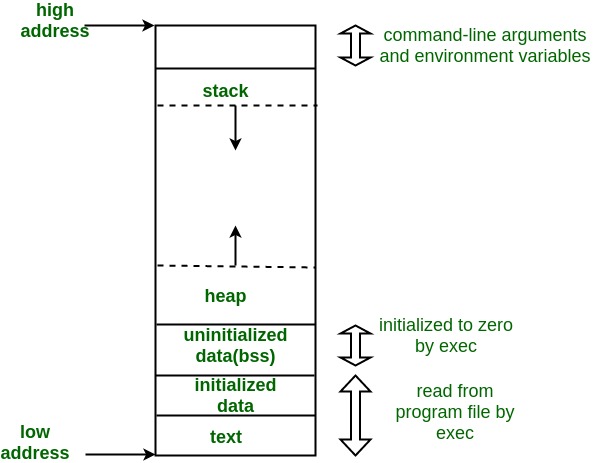
实际代码例子
1 | int a = 0; //全局初始化区 |
栈和堆对比
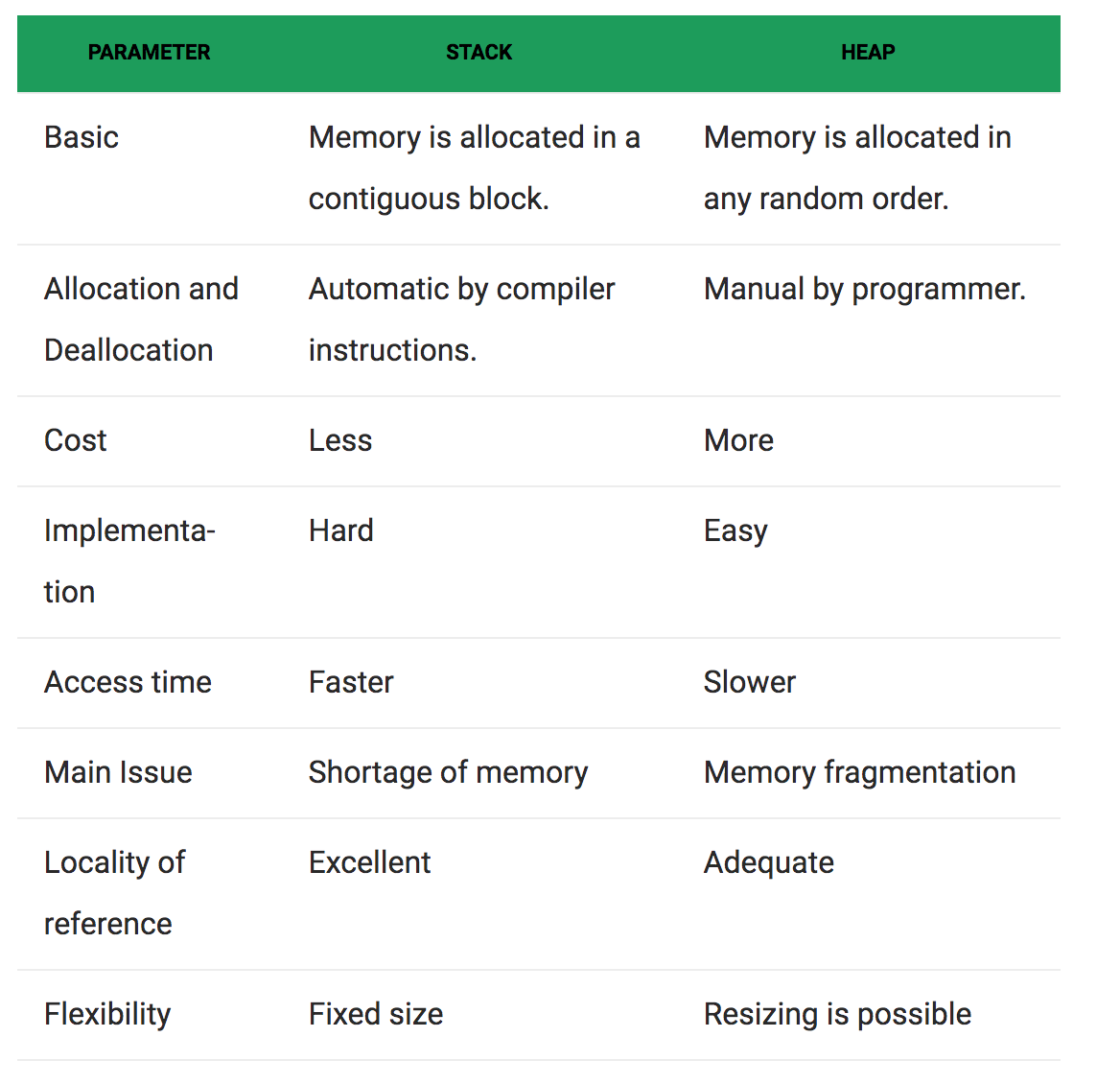
问答总结
内存分配方面:
堆:一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收.
栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。
申请方式方面:
堆:需要程序员自己申请,并指明大小。在c中malloc函数如p1 = (char *)malloc(10);在C++中用new运算符,但是注意p1、p2本身是在栈中的。因为他们还是可以认为是局部变量。
栈:由系统自动分配。 例如,声明在函数中一个局部变量 int b;系统自动在栈中为b开辟空间。
系统响应方面:
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
大小限制方面:
堆:是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
栈:栈的大小是固定的(是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,就stack overflow了,linux一般是8M。
效率方面:
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便,
栈:由系统自动分配,速度较快。但程序员是无法控制的。
存放内存方面:
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
栈:在函数调用时第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈,然后是函数中的局部变量。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
存取效率方面:
堆:char *s1 = “Hellow Word”;是在编译时就确定的;
栈:char s1[] = “Hellow Word”; 是在运行时赋值的;用数组比用指针速度要快一些,因为指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上直接读取。
Refence:
https://www.geeksforgeeks.org/stack-vs-heap-memory-allocation/